Holistycznie o technicznej stronie pracy z repozytorium i Code Review
Dlaczego teraz
Jestem w trakcie zbierania materiałów/spisywania/nagrywania tytułowego tematu. Bezpośrednim powodem, że robię to właśnie teraz jest potrzeba projektowa.
Po raz kolejny jestem w nowym zespole. Jest dużo do zrobienia w kwestii dobrych praktyk. Chcę zrobić wszystko co mogę żeby to przyspieszyć, poprzez danie tej wiedzy zespołowi w możliwie przystępny sposób.
To tylko jedna strona medalu. Druga jest bardziej istotna. Robiłem to już wiele razy i zrobię to jeszcze wiele razy. Tak jak to robi konsultant, który pomaga wielu różnym zespołom.
Przybliżę obecną sytuację. Nas – technicznych konsultantów jest dwóch, dział programistyczny firmy której pomagamy ma 20 osób. Jest bardzo dużo pracy do wykonania, a nas mało. Bardzo potrzebuję narzędzi, które pozwolą takie tranzycje lepiej skalować.
Ucinamy scope
Jak to się mówi w Pragmatic Coders „Dobrego Product Ownera poznaje się po tym ile rzeczy potrafi wyrzucić ze scope’u”
O czym NIE będzie:
- backlogu
- (feature toggle – to później)
- dobrej architekturze (ciekawsze wzorce, Hexagon, itp)
- testach (będzie, ale mało)
Co będzie
- Trunk Based Development
- Continous Integration
- Jedno repo – powiedzmy projekt w 7 osobowym zespole
- Dzielenie zadań na mniejsze a commitów na jeszcze mniejsze.
- Skuteczne code review:
- autymatyzacja kolejnych rzeczy
- gdy wystawiam CR to muszę się przyłożyć żeby Reviewerom było łatwiej
- ciągły refactoring (Boys Scout Rule) + refactoring przed feature/bugiem.
Przejście z A do B
Na te kilka tematów można znaleźć materiały i podrzucić zespołowi. Ale to nie takie proste 🙂
Trudno jest sprawić żeby firma/zespół/poszczególni ludzie zmienili swoje codzienne praktyki do których przywykli. Pokaże od kuchni „mój warsztat”, które sprawia, żeby zespół, który nie ma nic z wymienionych praktyk potrafił samodzielnie (bo będzie moment, kiedy przejdę do kolejnego zespołu) działać w oparciu o wszystkie te praktyki.
Idą „ciekawe czasy” na moim blogu i kanale youtube 🙂
Moje wystąpienie na KGD – Jak dzielić zadania, commity i Merge Requesty
🔊 Jak dostarczać w małych i stabilnych kawałkach.
🔊 Dokładnie zrozumieć i przegadać w zespole, ze coś dodatkowego (np. caching) może być dostarczone później.
🔊 Jak podchodzić do sugestii na Code Review, które za dużo zmieniają.
KDG – Krakowska Grupa Developerów .NET https://www.meetup.com/KGD-NET/
Video polecam przede wszystkim za bardzo profesjonalną jakość nagrania i obróbki. Wystąpiłem już w kilku miejscach i tak profesjonalnie jeszcze to nie było wykonane.
W jakich krokach zmigrować procesowanie eventu z formatu Avro na JSONa na Kafce
Chcemy zrobić tytułową podmianę na istniejącym evencie na PRODukcji, która musi ciągle działać (bez bezpiecznego okienka, kiedy możemy uznać, że system nic nie robi). Jest to event wewnętrzny naszego komponentu, nie dotyka to innych komponentów (microserwisów), które są osobnymi repozytoriami utrzymywanymi i deployowanymi przez inne zespoły.
Proponuje kroki:
- będzie nowy topic (pewnie będzie problem z nazwą, bo najlepsza pewnie będzie ta stara, ale niestety ona jest zajęta)
- dodanie konsumpcji eventu w formacie JSON z nowego topica (zakładam ze w jednym commicie i w jednym deployu, będzie tylko zmiana schematu i żadnej dodatkowej zmiany w logice)
- dodanie (ukryte za flaga na razie wyłączone) publiszowania na nowy topic
- sprawdzenie na DEV czy działa (włączenie flagi)
- kolejne środowiska (STAGE, PROD) * najpierw deploy * a później bezpiecznie sprawdzamy, czy po włączeniu flagi się dobrze procesuje
- gdy już na PROD działa to czyścimy kod z tworzenia i konsumowania starego eventu
Zalety tego podejścia
Ważne jest, żeby jednocześnie działała (przez jakiś czas) konsumpcja obydwu topic’ów. Unikamy sytuacji, że wstaje nowa wersja aplikacji i nagle zostały sprzed ułamka sekundy eventy stworzone w starym (AVRO) formacie, i już nigdy nie będą przetworzone.
Deploy na PROD nie jest twardo powiązany z przepięciem się na topic JSONowy. Nie musimy czekać na dobry moment (np. mały ruch), żeby zrobić deploy, tylko robimy to w dowolnym momencie (przy okazji zdeployowaly się pewne inne rzeczy, które sprawdzimy od razu). W dowolnym momencie później przepinamy się na nowy topic.
Trudniej będzie odkręcić deploy niż zmienić flagę, jeśli się okaże, że przeszło nam na DEV, oraz STAGE, ale są inne „cosie” (corner case) na PROD i tutaj się nie procesuje wszystko poprawnie.
Jakie odmiany nazw stosowac w kodzie – brytyjskie czy amerykanskie?
Ostatnio w jednym projekcie
Opowiem sytuację projektową, która wydarzyła się 2 tygodnie temu. Jest to projekt, który związany jest ze zmianami komunikacji w połowie komponentów używanych w Kitopi. Zdecydowanie duża rzeczy, w którą zaangażowane są zespoły z wielu komponentów. Trzeba więc połączyć założenia wielu osób, z których każda w swoim kontekście pewnie ma racje. Domenowa część jest oczywiście tym, co jest rzeczywiście trudne, ale ja dzisiaj nie o tym. Dzisiaj będzie o nazwach.
Pojawiło się takie pytanie.
ProductCatalog vs ProductCatalogue ?
Mój kontekst -> moje podejście
Ja bylem w tym drugim obozie (i od niego zacznę, bo to była moja jedyna perspektywa), czyli „ProductCatalogue”, wydawało mi się to oczywiste, bo:
– ten mój komponent, na co dzień rozmawia z biznesem i tam jest właśnie taka wersja używana
– wrzuciłem „catalog” w google i przekierowało na „catalogue” wiec wiem ze obie sa poprawne, ale jednak to drugie preferowane przynajmniej przez wyszukiwarkę
– od kilku miesięcy rozkminiamy domenowo ten kawałek i zawsze tak to nazywaliśmy
Argumenty pierwszego obozu:
– the first one is already in avro schema as well
– having two versions of the same field in the same application will be somehow schizopchrenic, eg. catalog received from menu will have to be passed to cx (Customer Contact Center) as cataloque etc.
Eureka
Komentarz, który dla mnie całkowicie rozwiązał dyskusje to:
„Should we bother so much about the form catalog vs catalgue ? The only difference is that one is US english, wheres the other is from british english”
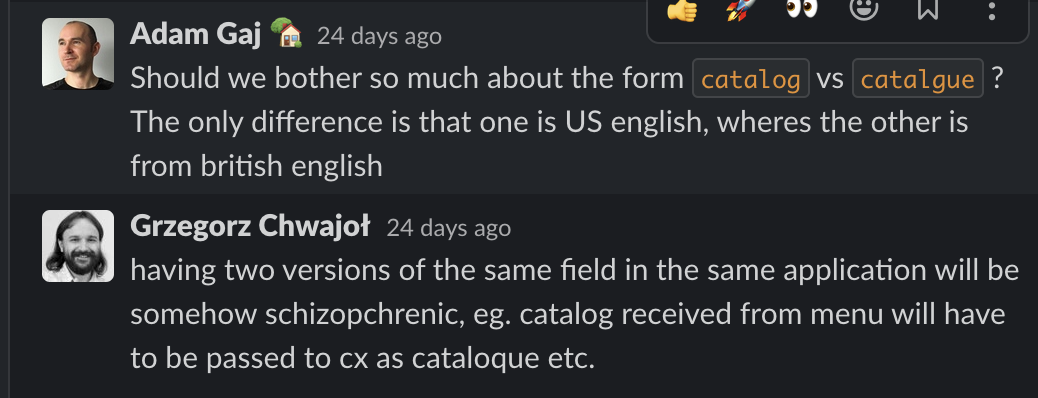
Na początku uznałem, ze to przecież oczywiste ze taka jest różnica między nimi i właśnie dlatego preferuje „catalogue”. Musiałem to przespać i następnego dnia zapytałem googla, czy używać en-us czy en-gb w IT i wszystkie się wyjaśniło:
https://stackoverflow.com/questions/157807/gb-english-or-us-english
przykłady to Color vs Colour. Ale nie dotyczy to tylko małych zmian w pisowni. Inne przykłady:
lift(br) – elevator(us)
car park (br) – parking lot (us)
(Śmieszne jest to, że jest to znana mi reguła, ale po prostu zapomniałem 🙂 )
Konsensus
Wtedy można było skończyć dyskusje
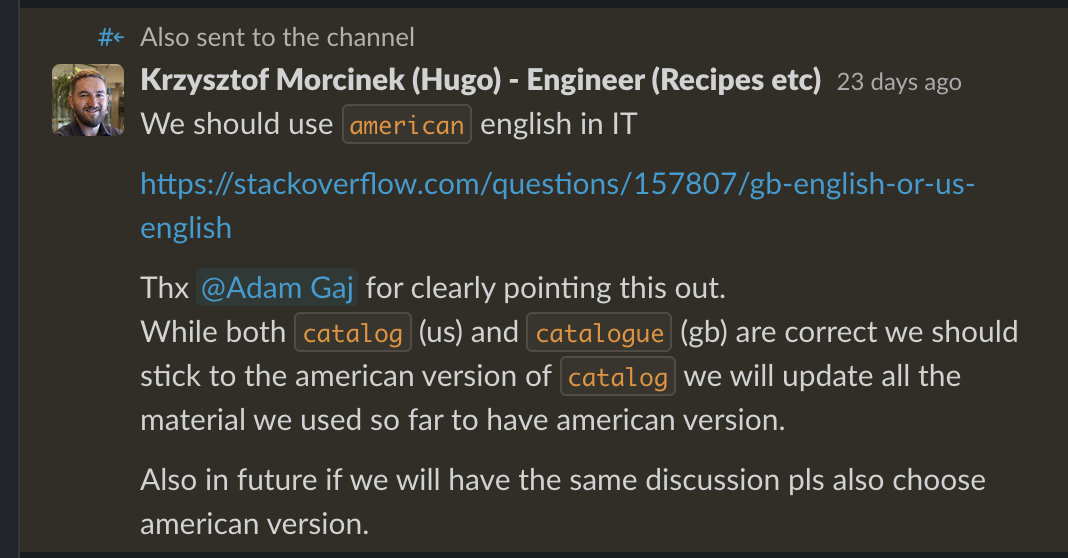
i zrobić rename’y.
Dlaczego to jest ważne
Jak już zostało to wyżej opisane, może to prowadzić do nieporozumień (schizofrenia 😉 ). W związku z tym trzeba coś wybrać. Taki proces wybierania może być czasem czasochłonny, bo np. coś już zaczęło być używane, a druga wersja jest poprawna i teraz naprawienie tego może mieć niezerowy koszt.
Dlaczego reguła, żeby brać US, tak mi się podoba — bo jest prosta.
A jak będziemy pisać w rozmowach z biznesem?
Raczej pozostaniemy przy brytyjskich wersjach. Gdyby nasz biznes był w US to może byłoby inaczej, ale wywodzimy się z Dubaju i tam raczej british english obowiązuje.
Cala ta dyskusja zajęła nam mniej niż napisanie tego artykułu. Jeśli używa się rzeczowych argumentów to szybko udaje się dojść do konsensusu.
O pracoholiźmie z książki „Rework”
Tekst cytuję z książki Rework, którą polecam.
Jest to jeden z rozdziałów.
Pracoholizm
W naszej kulturze idea pracoholizmu jest wynoszona na piedestał. Słyszy się o ludziach ślęczących po nocach i nocujących w biurze. Za punkt honoru stawiają sobie wypruwanie żył nad projektem. Ich poświęcenie i wysiłki nie mają końca.
Pracoholizm jest nie tylko niepotrzebny, ale również głupi. To, że dużo pracujesz, nie oznacza, iż bardziej Ci na pracy zależy albo że więcej robisz. Po prostu: poświęcasz pracy dużo czasu.
Pracoholicy zwykle stwarzają więcej problemów, niż sami potrafią rozwiązać. Przede wszystkim tak wytężony wysiłek na dłuższą metę jest niemożliwy. Kiedy osobę pracującą ponad miarę dotknie wypalenie zawodowe (a na pewno to nastąpi), przeżyje ten kryzys znacznie gorzej niż inny pracownik.
Ludzie nadmiernie poświęcający się życiu zawodowemu nie rozumieją, na czym polega praca. Starają się rozwiązywać problemy, poświęcając im długie godziny. Swoje intelektualne lenistwo próbują pokryć fizycznym wysiłkiem. W efekcie otrzymują nieeleganckie rozwiązania.
Tego rodzaju ludzie potrafią nawet wywoływać kryzysy. Nie szukają sposobów podniesienie efektywności swojej pracy, ponieważ właściwie lubią zostawać po godzinach. Dzięki temu czują się jak bohaterowie. Piętrzą problemy (często mimowolnie) po to tylko, żeby mogli więcej pracować.
Ludzie, którzy pracują “tylko” w normalnych godzinach, czują, że odstają. W ten sposób pracoholicy wpędzają innych w poczucie winy, a ogólnie morale w organizacji spada. Taka sytuacja sprzyja również powstawaniu zwyczaju bezproduktywnego przesiadywania po godzinach bez wyraźnej potrzeby.
Jeśli jesteś zajęty tylko pracą, nie potrafisz dokonywać słusznych wyborów. Twoje wartości wypaczają się i nie umiesz podejmować właściwych decyzji. Nie jesteś w stanie stwierdzić, jakim sprawom warto poświęcić dodatkowe wysiłki, a jakie wymagają nadprogramowych nakładów pracy. Po pewnym czasie jesteś wykończony. Nikt nie podejmuje trafnych decyzji, kiedy jest zmęczony.
W końcu pracoholicy tak naprawdę nie osiągają więcej od osób z zdrowym podejściem do pracy. Być może uważają się za perfekcjonistów, ale w rzeczywistości marnują swój czas na skupianiu się na nieistotnych szczegółach, zamiast zabrać się do wykonywania kolejnego zadania.
Pracoholicy nie są bohaterami. Nie poprawiają sytuacji, tylko pracują cały dzień. Prawdziwi bohater w tym czasie jest już w domu, ponieważ znalazł szybszy sposób na wykonanie swoich obowiązków.
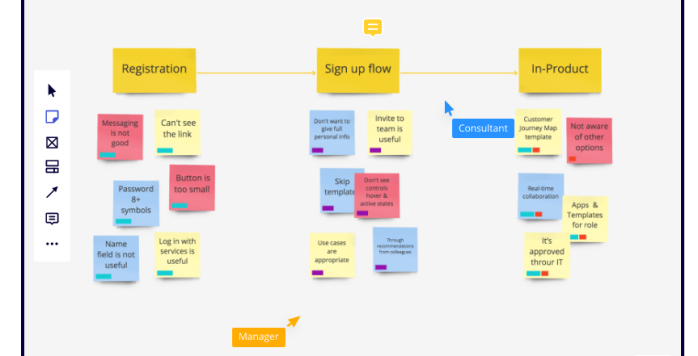
MVP approach at Kitopi
Quick screencast about MVP approach (Minimum Viable Product), we use at Kitopi like in every startup.
Example is easy process (in Miro board) we were working at and examples how to make it simpler and smaller.
2 pictures:
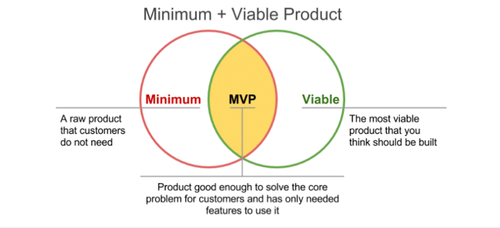
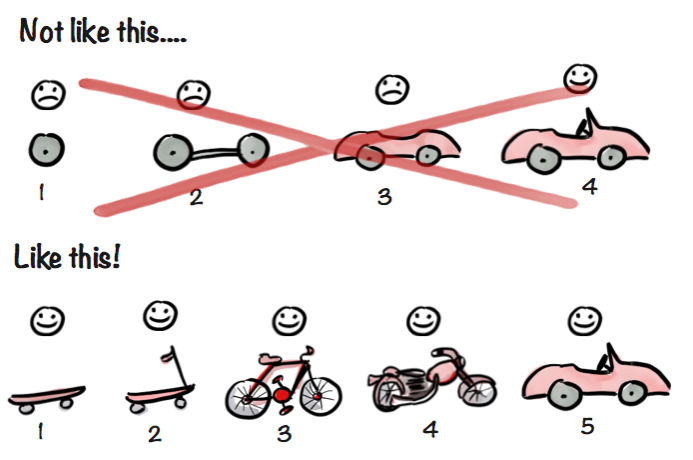
Second one comes from How to Build a Minimum Viable Product (MVP)?
Poznać własne predyspozycje – Mój Test Gallupa
Zrobiłem sobie taki właśnie test, inna jego nazwa to Strengths Finder lub Gallup Strengths Finder. Warto lepiej poznać siebie. Nie jest to płytki test typu czy jesteś bardzo introwertykiem czy bardziej tym przeciwnym. Dostępna jest duża ilość materiałów, które pozwalają dobrze pracować z naszymi „mocnymi stronami”.
Co to właściwie jest moimi własnymi słowami na teraz:
Każdy człowiek ma pewne predyskozycje do robienia rzeczy we właściwy mu sposób. Na razie ani dobre ani złe, po prostu predyspozycje. Jeśli jestem bardziej świadomy tych mechanizmów to mogę nad nimi pracować aby „predyspozycje” stały się mocnymi stronami zamiast ciemnymi stronami.
Polecam materiały Dominika, skąd można w szczegółach poczytać o każdym talencie.
Dominik Juszczyk – Silne strony
Jak zrobić test StrengthsFinder po polsku
Mój test zrobiłem w 2017 i moje dominujące talenty to
-
Self-Assurance (Wiara w siebie)
Osoby, które szczególnie wyróżnia cecha Wiary w siebie, są przekonane, że mają zdolności podejmowania ryzyka i kierowania własnym życiem. Mają one wewnętrzny kompas, który zapewnia im pewność w podejmowaniu decyzji./blockquote>
-
Learner (Uczenie się)
Osoby, które szczególnie wyróżnia cecha Uczenia się, mają silne pragnienie nauki i ciągłego doskonalenia siebie. Bardziej ekscytuje je sam proces uczenia się niż jego rezultaty.
-
Maximizer (Maksymalista)
Osoby, które szczególnie wyróżnia cecha Maksymalista, koncentrują się na silnych stronach jako sposobie stymulowania doskonałości osobistej oraz zespołowej. Starają się przekształcić coś, co już jest dobre, w coś, co będzie doskonałe.
-
Command (Dowodzenie)
Osoby, które szczególnie wyróżnia cecha Dowodzenia, są zauważalne i wywierają wpływ na innych. Potrafią przejąć kontrolę nad sytuacją i podejmować decyzje.
-
Activator (Aktywator)
Osoby, które szczególnie wyróżnia cecha Aktywator, przyczyniają się do realizacji zadań dzięki temu, że potrafią swoje myśli obrócić w czyn. Swoje zadania chcą wykonać, a nie tylko o nich mówić.
[Screencast] Podejście Minimum Viable Product
Krótki screencast o podejściu MVP (Minimum Viable Product) z którego korzystamy w Kitopi jak w każdym startupie.
Przykład prostego procesu (w Miro) nad którym aktualnie pracujemy i przykłady jak można go okroić.
2 obrazki warte 2 tysiące słów 😉
Drugi obrazek pochodzi z How to Build a Minimum Viable Product (MVP)?
[Screencast] Podstawy Miro Board
Wprowadzenie do Miro – narzędzia które jest tablicą online do tworzenia diagramów, łączenia karteczek i tworzenia map myśli.
Dzisiaj tylko o najprostszych karteczkach na przykładzie prostego biznesowego flow i zmian podczas poznawania problemu biznesowego (tworzenie przepisów do przygotowania potraw).
Inna przykładowa tablica:
[Podcast] Po co refinement i jak estymować
Opowiadam na jakie pytania sobie odpowiadać podczas refinementu oraz jakich technik estymacji lubię używać. Doświadczenie ostatniego roku pracy w projekcie w Kitopi (częsta rola Scrum Mastera).
Polecam tzw. koszulki:

Sponsorem tego odcinek jest koncepcja „Mapa myśli” (Mind map). Bardzo pomaga mi to narzędzie przygotować się merytorycznie do tego podcastu i fajnie po takiej mapie przechodzi się podczas nagrywania.
Poniżej mind mapa, która była użyta w tym odcinku



